
一种新的人工智能(AI)模型刚刚在一项旨在衡量“一般智力”的测试中取得了与人类相当的成绩。
12月20日,OpenAI的o3系统在ARC-AGI基准测试中得分为85%,远高于此前人工智能的最佳得分55%,与人类的平均得分相当。它在一次非常困难的数学测试中也取得了很好的成绩。
创造通用人工智能(AGI)是所有主要人工智能研究实验室的既定目标。乍一看,OpenAI似乎至少朝着这个目标迈出了重要的一步。
尽管怀疑依然存在,但许多人工智能研究人员和开发人员感到有些事情发生了变化。对许多人来说,人工智能的前景现在似乎比预期的更真实、更紧迫、更接近。他们是对的吗?
要理解o3结果意味着什么,您需要了解ARC-AGI测试的全部内容。用技术术语来说,这是对人工智能系统适应新事物的“样本效率”的测试——系统需要看到多少个新情况的例子才能弄清楚它是如何工作的。
像ChatGPT (GPT-4)这样的人工智能系统不是很有效。它在数以百万计的人类文本样本上进行了“训练”,构建了关于最可能的单词组合的概率“规则”。
其结果是在普通任务中非常出色。它不擅长处理不常见的任务,因为关于这些任务的数据(样本)较少。

除非人工智能系统能够从少量的例子中学习并适应更高的样本效率,否则它们只会被用于非常重复的工作和偶尔失败是可以容忍的工作。
从有限的数据样本中准确地解决以前未知或新问题的能力被称为泛化能力。它被广泛认为是智力的必要甚至基本要素。
ARC-AGI基准测试使用像下面这样的小网格正方形问题来测试样本的有效适应性。人工智能需要找出将左边的网格变成右边网格的模式。

每个问题给出三个例子来学习。然后,人工智能系统需要找出从这三个例子“概括”到第四个例子的规则。
这些很像智商测试有时你可能记得在学校。
我们不知道OpenAI是如何做到的,但结果表明,o3模型具有很强的适应性。从几个例子中,它发现了可以推广的规则。
为了找出一个模式,我们不应该做任何不必要的假设,或者比我们真正需要的更具体。从理论上讲,如果你能找出“最弱”的规则,那么你就能最大限度地提高自己适应新情况的能力。
最弱规则是什么意思?技术定义很复杂,但较弱的规则通常可以用更简单的语句来描述。
在上面的例子中,这个规则的简单英语表达可能是这样的:“任何有突出线的形状都会移动到该线的末端,并‘覆盖’与之重叠的任何其他形状。”
虽然我们不知道OpenAI是如何实现这个结果的,但他们似乎不太可能故意优化o3系统来寻找弱规则。然而,要想在ARC-AGI任务中取得成功,它必须找到它们。
我们确实知道OpenAI从o3模型的通用版本开始(它与大多数其他模型不同,因为它可以花更多的时间“思考”难题),然后专门为ARC-AGI测试训练它。
法国人工智能研究人员Francois Chollet设计了这个基准,他认为o3会通过不同的“思维链”来描述解决任务的步骤。然后,它会根据一些松散定义的规则或“启发式”选择“最佳”。
这与b谷歌的AlphaGo系统通过搜索不同可能的走法序列来击败世界围棋冠军的方式“没有什么不同”。
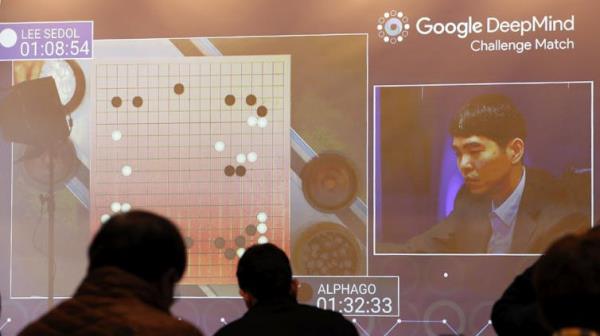
你可以把这些思维链想象成适合这些例子的程序。当然,如果它像围棋AI,那么它就需要一个启发式或宽松的规则来决定哪个程序是最好的。
可能会生成数千个不同的看似同样有效的程序。这个启发式可以是“选择最弱的”或“选择最简单的”。
然而,如果它像AlphaGo那样,那么他们只是让人工智能创造了一个启发式。这就是AlphaGo的过程。谷歌训练了一个模型来评估不同的动作序列是好是坏。
接下来的问题是,这真的更接近AGI吗?如果这就是o3的工作原理,那么底层模型可能不会比以前的模型好多少。
模型从语言中学习的概念可能不再比以前更适合泛化。相反,我们可能只是看到了一个更普遍的“思维链”,通过额外的训练步骤找到了一个专门针对这个测试的启发式。一如既往,检验将在布丁中。
几乎关于o3的一切都是未知的。OpenAI只向一些媒体披露了一些信息,并向少数研究人员、实验室和人工智能安全机构进行了早期测试。
真正了解o3的潜力将需要广泛的工作,包括评估、了解其能力的分布、失败的频率和成功的频率。
当o3最终释放时,我们将更好地了解它是否与普通人一样具有适应能力。
如果是这样,它可能会产生巨大的、革命性的经济影响,开启一个自我完善的智能加速发展的新时代。我们将需要为AGI本身制定新的基准,并认真考虑应该如何治理它。
如果没有,那么这仍然是一个令人印象深刻的结果。然而,日常生活将保持不变。










